課題は①と②の2つありますので、注意してください。
e061454は両課題終了1番乗りです。お疲れ様でした。
本演習は終了しましたので、他の授業の試験対策でがんばってください。
同様に
e061458
e061490
e061482
e051266
e051118
e071326
e071331
e071322
も、両課題終了を確認しました。お疲れ様でした。
e041501
確認しました。課題終了。
e071306
同じく確認しました。課題終了。
e061459
e061479
e051501
e061473
e061468
2008年8月6日:課題終了確認しました。
e061477さんは前回記事の課題サンプルかe061454さんの課題を見てください。

課題①(横断面データ)終了
e041501
e051118
e051266
e061454
e061458
e061459
e061479
e061482
e061490
e071306
e071322
e071326
e071331
e051501
e061473
e061468
課題②(時系列データ)終了
e041501
e051118
e051266
e051501
e061454
e061458
e061459
e061468
e061473
e061479
e061482
e061490
e071306
e071326
e071331
e051501
e061454は両課題終了1番乗りです。お疲れ様でした。
本演習は終了しましたので、他の授業の試験対策でがんばってください。
同様に
e061458
e061490
e061482
e051266
e051118
e071326
e071331
e071322
も、両課題終了を確認しました。お疲れ様でした。
e041501
確認しました。課題終了。
e071306
同じく確認しました。課題終了。
e061459
e061479
e051501
e061473
e061468
2008年8月6日:課題終了確認しました。
e061477さんは前回記事の課題サンプルかe061454さんの課題を見てください。

課題①(横断面データ)終了
e041501
e051118
e051266
e061454
e061458
e061459
e061479
e061482
e061490
e071306
e071322
e071326
e071331
e051501
e061473
e061468
課題②(時系列データ)終了
e041501
e051118
e051266
e051501
e061454
e061458
e061459
e061468
e061473
e061479
e061482
e061490
e071306
e071326
e071331
e051501
Posted by ryu908 at
07:57
│Comments(9)
サンプルをあげておきます。
課題1 横断面データの例
課題2 時系列データの例
課題2について下記の方は、終了とします。
できれば推計結果のモデルも記録しておいてほしかったところです。
ですが、早めのUPなので高評価となります。
e061482
e061490
e071331
e071326
e061479
e061479さんのように図をサムネイル表示すると見やすくて助かります。
e071306は残念ながら、鉱工業生産指数はサンプルなので課題とはなりません。
別の変数で予測図の作成を試みてください。
課題2が終わったら、課題1のほうをやっといてください。
サンプルと全く同じではなく、データを1変数でもいいから差し替えてみてください。
課題1 横断面データの例
課題2 時系列データの例
課題2について下記の方は、終了とします。
できれば推計結果のモデルも記録しておいてほしかったところです。
ですが、早めのUPなので高評価となります。
e061482
e061490
e071331
e071326
e061479
e061479さんのように図をサムネイル表示すると見やすくて助かります。
e071306は残念ながら、鉱工業生産指数はサンプルなので課題とはなりません。
別の変数で予測図の作成を試みてください。
課題2が終わったら、課題1のほうをやっといてください。
サンプルと全く同じではなく、データを1変数でもいいから差し替えてみてください。
Posted by ryu908 at
17:49
│Comments(20)
時系列データの解析と予測
時系列データを料理するために身につけるべきこと
① データの生成メカニズムを知る
② 予測する
データの発生メカニズム(DGP:data generating process)を解き明かすとは、すなわち何らかの方程式などのモデルに当てはめることと思えばよい。式が分かれば、予測も簡単である。しかし、統計的手法は万能ではないので、特別な前提をおく。
ここでは
●平均が一定(通常は標準化して0とおくと、やり易い)
●分散も一定(ずっと大きくなっていくとか、小さくなっていくとかしない)
この条件をみたすものを、とりあえず「定常時系列」とよぶ。
ちなみに、そうじゃないのを「非定常」という。
なので、実際のデータがこの条件に合わないとき、何らかの変換を加えて定常化すればよい。
1.データの生成機構を調べる方法
最初にトレンド(T)があるかをみる。
次は周期性(C)
そして季節性(S)などなど
→ プロットしたデータを見て特徴を記述する。
データが非定常なら、定常にする。
色々な方法がある。今回は差分をする。
2.予測する
今回は汎用性の高いARIMA/SARIMAをつかう。
ARFIMAやGARCH、カルマンフィルターなど時系列データの予測手法はデータの発生メカニズムに関連する。
ちなみに原典はBox=Jenkins(1976)『TIME SERIES ANALYSIS ,forecasting and control』です。
モデルの推計結果を使って、予測用の系列を作成し、描画出力する。
実際の予測作業はモデルの同定と診断に多くの労力を割き、時間もかかるが、今回は一通りの出力を得る練習と割り切って
ARIMAモデルの推計は
AR過程を1から3次程度
MA過程も1から3次程度
和分は1にする。
SARIMAの場合の
季節和分も1にする。
例えば
ARIMA(1,1,1)はAR1次、和分1階、MA1次となる。
ARIMA(2,1,1)はAR2次、和分1階、MA1次となる。
ARIMA(1,1,2)はAR1次、和分1階、MA2次となる。
ARIMA(2,1,2)はAR2次、和分1階、MA2次となる。
とりあえず、この4つ(SARIMAを除いて)を試して、いちばん良さげなものを採用し、予測系列を作成する。
※ モデルの診断に興味がある学生さんはAIC、SBICといったモデル選択のための統計量や、自己相関、編自己相関の詳しい見方を身につける必要がある。株で一儲け目論んでいる方は計量経済学の講義の時系列分析のパートを気合いをいれて勉強しましょう。



山本拓『経済時系列の分析』より
データはこれです。
例によって、ワークシート名[trianing]B1:B229を選択、コピーして
x<-read.table("clipboard",header=T)
でRに取り込む
このデータは1987年1月からなのでtsオブジェクトに変換して、表示
ty1<-ts(x,start=c(1987,1),freq=12)
plot(ty1)
TCSI分離で変動特性の目視
plot(decompose(ty1))
トレンドと周期成分をスペクトルで目視
spectrum(ty1)
ついでに
spectrum(ty1,method="ar")
最初に自己相関と編自己相関をみる
par(mfrow=c(2,1))
acf(ty1,lag.max=100)
pacf(ty1,lag.max=100)
par(mfrow=c(1,1))
トレンドを除去するか、1階差分でみる
dty1<-diff(ty1)
par(mfrow=c(3,1))
plot(dty1)
acf(dty1,lag.max=60)
pacf(dty1,lag.max=60)
par(mfrow=c(1,1))
とりあえず2次のAR、2次のMA、1次の差分でARIMAを推計する。
arima01<-arima(ty1,order=c(2,1,2))
arima01
この式は以下のように定式化できる
Yt=0.977Y(t-1)-0.1273Y(t-2)-0.1511m(t-1)+0.2913m(t-2)
Rのarima関数は残差系列しか出力されないので、原系列から残差を引いて、予測値系列とする
par(mfrow=c(2,1))
tres<-arima01$resid
ty1_hat<-ty1-tres
plot(ty1)
lines(ty1_hat,lty=2,col=2)
plot(tres,type="l",col=4)
abline(h=mean(tres))
par(mfrow=c(1,1))
予測する。xtとした期間にちゅういすること
pred1<-predict(arima01,n.ahead=12)
xt<-c(2005,2007)
y1es<-pred1$pred
plot(ty1,xlim=xt)
lines(y1es,col=2)
以下はやってもやらなくてもよいけど、参考にしてくだされ
① 信頼限界付きかっこいい予測結果の出力
pred1<-predict(arima01,n.ahead=12)
xt<-c(2005,2007)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
② 出力期間を変更してプロットする
pred1<-predict(arima01,n.ahead=24)
xt<-c(1987,2008)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
③ 参考までに出力タイプ別でやってみた
xt<-c(2005,2007)
plot(ty1,type="p",xlim=xt,ylim=yl)
lines(y1es,type="p")
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
++++++++++++++++++++++++++++
季節階差付きSARIMAモデルの練習
++++++++++++++++++++++++++++
セルC1:C241を選択してコピー
x<-read.table("clipboard",header=T)
で読み込み、tsオブジェクトに変換して、プロット
ty1<-ts(x,start=c(1987,1),freq=12)
plot(ty1)
par(mfrow=c(2,1))
acf(ty1,lag.max=100)
pacf(ty1,lag.max=100)
par(mfrow=c(1,1))
SARIMAの場合12か月毎の周期性があるためseasonal=list(order=c(1,1,1),period=12)というオプションを追加する。詳しくはhelp(arima)としてヘルプをみてみること。
sarima01<-arima(ty1,order=c(2,1,2),seasonal=list(order=c(1,1,1),period=12))
sarima01
推計結果の出力
par(mfrow=c(2,1))
tres<-sarima01$resid
ty1_hat<-ty1-tres
plot(ty1)
lines(ty1_hat,lty=2,col=2)
plot(tres,type="l",col=4)
abline(h=mean(tres))
par(mfrow=c(1,1))
12か月先の予測
pred1<-predict(sarima01,n.ahead=12)
xt<-c(2005,2009)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
24か月先の予測(上との違いを確認してください)
pred1<-predict(sarima01,n.ahead=24)
xt<-c(1987,2009)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
ここまで出来たらIIP(鉱工業生産指数)で練習してみます。
時系列データを料理するために身につけるべきこと
① データの生成メカニズムを知る
② 予測する
データの発生メカニズム(DGP:data generating process)を解き明かすとは、すなわち何らかの方程式などのモデルに当てはめることと思えばよい。式が分かれば、予測も簡単である。しかし、統計的手法は万能ではないので、特別な前提をおく。
ここでは
●平均が一定(通常は標準化して0とおくと、やり易い)
●分散も一定(ずっと大きくなっていくとか、小さくなっていくとかしない)
この条件をみたすものを、とりあえず「定常時系列」とよぶ。
ちなみに、そうじゃないのを「非定常」という。
なので、実際のデータがこの条件に合わないとき、何らかの変換を加えて定常化すればよい。
1.データの生成機構を調べる方法
最初にトレンド(T)があるかをみる。
次は周期性(C)
そして季節性(S)などなど
→ プロットしたデータを見て特徴を記述する。
データが非定常なら、定常にする。
色々な方法がある。今回は差分をする。
2.予測する
今回は汎用性の高いARIMA/SARIMAをつかう。
ARFIMAやGARCH、カルマンフィルターなど時系列データの予測手法はデータの発生メカニズムに関連する。
ちなみに原典はBox=Jenkins(1976)『TIME SERIES ANALYSIS ,forecasting and control』です。
モデルの推計結果を使って、予測用の系列を作成し、描画出力する。
実際の予測作業はモデルの同定と診断に多くの労力を割き、時間もかかるが、今回は一通りの出力を得る練習と割り切って
ARIMAモデルの推計は
AR過程を1から3次程度
MA過程も1から3次程度
和分は1にする。
SARIMAの場合の
季節和分も1にする。
例えば
ARIMA(1,1,1)はAR1次、和分1階、MA1次となる。
ARIMA(2,1,1)はAR2次、和分1階、MA1次となる。
ARIMA(1,1,2)はAR1次、和分1階、MA2次となる。
ARIMA(2,1,2)はAR2次、和分1階、MA2次となる。
とりあえず、この4つ(SARIMAを除いて)を試して、いちばん良さげなものを採用し、予測系列を作成する。
※ モデルの診断に興味がある学生さんはAIC、SBICといったモデル選択のための統計量や、自己相関、編自己相関の詳しい見方を身につける必要がある。株で一儲け目論んでいる方は計量経済学の講義の時系列分析のパートを気合いをいれて勉強しましょう。



山本拓『経済時系列の分析』より
データはこれです。
例によって、ワークシート名[trianing]B1:B229を選択、コピーして
x<-read.table("clipboard",header=T)
でRに取り込む
このデータは1987年1月からなのでtsオブジェクトに変換して、表示
ty1<-ts(x,start=c(1987,1),freq=12)
plot(ty1)
TCSI分離で変動特性の目視
plot(decompose(ty1))
トレンドと周期成分をスペクトルで目視
spectrum(ty1)
ついでに
spectrum(ty1,method="ar")
最初に自己相関と編自己相関をみる
par(mfrow=c(2,1))
acf(ty1,lag.max=100)
pacf(ty1,lag.max=100)
par(mfrow=c(1,1))
トレンドを除去するか、1階差分でみる
dty1<-diff(ty1)
par(mfrow=c(3,1))
plot(dty1)
acf(dty1,lag.max=60)
pacf(dty1,lag.max=60)
par(mfrow=c(1,1))
とりあえず2次のAR、2次のMA、1次の差分でARIMAを推計する。
arima01<-arima(ty1,order=c(2,1,2))
arima01
この式は以下のように定式化できる
Yt=0.977Y(t-1)-0.1273Y(t-2)-0.1511m(t-1)+0.2913m(t-2)
Rのarima関数は残差系列しか出力されないので、原系列から残差を引いて、予測値系列とする
par(mfrow=c(2,1))
tres<-arima01$resid
ty1_hat<-ty1-tres
plot(ty1)
lines(ty1_hat,lty=2,col=2)
plot(tres,type="l",col=4)
abline(h=mean(tres))
par(mfrow=c(1,1))
予測する。xtとした期間にちゅういすること
pred1<-predict(arima01,n.ahead=12)
xt<-c(2005,2007)
y1es<-pred1$pred
plot(ty1,xlim=xt)
lines(y1es,col=2)
以下はやってもやらなくてもよいけど、参考にしてくだされ
① 信頼限界付きかっこいい予測結果の出力
pred1<-predict(arima01,n.ahead=12)
xt<-c(2005,2007)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
② 出力期間を変更してプロットする
pred1<-predict(arima01,n.ahead=24)
xt<-c(1987,2008)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
③ 参考までに出力タイプ別でやってみた
xt<-c(2005,2007)
plot(ty1,type="p",xlim=xt,ylim=yl)
lines(y1es,type="p")
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
++++++++++++++++++++++++++++
季節階差付きSARIMAモデルの練習
++++++++++++++++++++++++++++
セルC1:C241を選択してコピー
x<-read.table("clipboard",header=T)
で読み込み、tsオブジェクトに変換して、プロット
ty1<-ts(x,start=c(1987,1),freq=12)
plot(ty1)
par(mfrow=c(2,1))
acf(ty1,lag.max=100)
pacf(ty1,lag.max=100)
par(mfrow=c(1,1))
SARIMAの場合12か月毎の周期性があるためseasonal=list(order=c(1,1,1),period=12)というオプションを追加する。詳しくはhelp(arima)としてヘルプをみてみること。
sarima01<-arima(ty1,order=c(2,1,2),seasonal=list(order=c(1,1,1),period=12))
sarima01
推計結果の出力
par(mfrow=c(2,1))
tres<-sarima01$resid
ty1_hat<-ty1-tres
plot(ty1)
lines(ty1_hat,lty=2,col=2)
plot(tres,type="l",col=4)
abline(h=mean(tres))
par(mfrow=c(1,1))
12か月先の予測
pred1<-predict(sarima01,n.ahead=12)
xt<-c(2005,2009)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
24か月先の予測(上との違いを確認してください)
pred1<-predict(sarima01,n.ahead=24)
xt<-c(1987,2009)
y1es<-pred1$pred
sig1<-pred1$se
tyl<-y1es-2*sig1
tyu<-y1es+2*sig1
yl<-c(min(ty1,tyl),max(ty1,tyu))
plot(ty1,xlim=xt,ylim=yl)
lines(y1es)
lines(tyl,lty=2,col=4)
lines(tyu,lty=2,col=4)
ここまで出来たらIIP(鉱工業生産指数)で練習してみます。
Posted by ryu908 at
16:32
│Comments(18)
7月2日のタイタニック号の決定木のグラフ出力の課題で、
同日未終了の学生で、7月9日に提出された方々です。
e051501:確認しました.OKです.
e061454:残念、UPされていないようです
e061475:確認しました.OKです.
e061477:確認しました.OKです.
e061479:UPされていないようですが、UPで出席扱いとします.
e071306:確認しました.OKです.
e071322:確認しました.OKです.
e071326:確認しました.OKです.
e071331:確認しました.OKです.
約2名を除いて、おつかれさまでした。
残念、UPされていないようです
同日未終了の学生で、7月9日に提出された方々です。
e051501:確認しました.OKです.
e061454:残念、UPされていないようです
e061475:確認しました.OKです.
e061477:確認しました.OKです.
e061479:UPされていないようですが、UPで出席扱いとします.
e071306:確認しました.OKです.
e071322:確認しました.OKです.
e071326:確認しました.OKです.
e071331:確認しました.OKです.
約2名を除いて、おつかれさまでした。
残念、UPされていないようです
Posted by ryu908 at
19:41
│Comments(2)
サンプルのデータファイルを作成しました。
まず、最初の作業は私の真似をしてください。
それから、皆さん独自の作業をしてみて下さい。
今回はクロスセクションデータ
次回は時系列データの解析演習をする予定です。
クロスセクションは構造分析(分類や潜在構造などの要因分析)が主目標です。
(タイムシリーズは予測や歴史的シミュレーションなど)
これがデータファイルです。
このファイルは、前に紹介した沖縄県統計課のLinkから
「e-Stat 政府統計の総合窓口」をたどって
「 都道府県・市区町村のすがた」からとったデータです。
ワークシート「proc」はオリジナルのデータから、分析してみたい指標を整形して取り出したものです。
まず6行目に、編集しやすいように変数名をつけています。
セルB6からM53の範囲を選択して
→ ① B6をクリック
② 「shift」キーを押しながらセルM53をクリック
③ 「Ctrl」+「C」キーを押してコピー
Rにregionというデータ名でセットする
region<-read.table("clipboard",header=T)
と入力して、リターン
下の2行はデータの確認でパッケージ「relimp」をインストールしていない方はやらなくてもよい
library(relimp)
showData(region)
Rコマンダーを起動する。
library(Rcmdr)
散布図行列や立体図示をして、データを眺める。
データ間に規則性や法則性があれば、記述する。
Rコマンダーが起動しない場合は、次のスクリプトを入力してみる。
これはRコマンダーの出力から転記したもの。
library(car)
scatterplot.matrix(~x1+x10+x11+x2+x3+x4+x6+x7+x8+x9 | x5, reg.line=lm, smooth=TRUE, span=0.5, diagonal= 'histogram', by.groups=TRUE, data=region)
変数x5はx4がプラスなら+、マイナスならーと変換したものである。
エクセルのif関数を使用(よく使う)
G7:=IF(F7>0,"+",IF(F7=0,"0","-"))
最下行までコピーする。
このx4を目的変数にして、CART(決定木、回帰木)を行う
変数x5を除くこと。
ライブラリーの読み込み
library(rpart)
regt<-rpart(x4~x1+x2+x3+x6+x7+x8+x9+x10+x11,data=region)
regt
plot(regt,margin=0.1)
text(regt,use.n=T)
何かわかったことがあるだろうか?
ここまで例を参考に、新たな変数を追加したり削除したり、加工したりして各自で絵を描いてみてください。
数字を眺めているだけでは分からなかいことでも、多変量散布図やCARTを描くことで何か、面白い情報が発見できるかもしれません。
~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~
前回、描画できなかった人は、描画してupしといてください。
前回の作業のトレース ↓
タイタニック号データの描画例
titn<-read.table("clipboard",header=T)
names(titn)
summary(titn)
titnr<-rpart(survived~pclass+age+sex,data=titn)
plot(titnr,margin=0.1)
text(titnr,use.n=T)
結果を見やすいように改良する
変数”suvived”は0か1の2値データなので、
関数:factor()を使って、2値化する。
titnr<-rpart(factor(survived)~pclass+age+sex,data=titn)
plot(titnr,margin=0.1)
text(titnr,use.n=T)
titnr
まず、最初の作業は私の真似をしてください。
それから、皆さん独自の作業をしてみて下さい。
今回はクロスセクションデータ
次回は時系列データの解析演習をする予定です。
クロスセクションは構造分析(分類や潜在構造などの要因分析)が主目標です。
(タイムシリーズは予測や歴史的シミュレーションなど)
これがデータファイルです。
このファイルは、前に紹介した沖縄県統計課のLinkから
「e-Stat 政府統計の総合窓口」をたどって
「 都道府県・市区町村のすがた」からとったデータです。
ワークシート「proc」はオリジナルのデータから、分析してみたい指標を整形して取り出したものです。
まず6行目に、編集しやすいように変数名をつけています。
セルB6からM53の範囲を選択して
→ ① B6をクリック
② 「shift」キーを押しながらセルM53をクリック
③ 「Ctrl」+「C」キーを押してコピー
Rにregionというデータ名でセットする
region<-read.table("clipboard",header=T)
と入力して、リターン
下の2行はデータの確認でパッケージ「relimp」をインストールしていない方はやらなくてもよい
library(relimp)
showData(region)
Rコマンダーを起動する。
library(Rcmdr)
散布図行列や立体図示をして、データを眺める。
データ間に規則性や法則性があれば、記述する。
Rコマンダーが起動しない場合は、次のスクリプトを入力してみる。
これはRコマンダーの出力から転記したもの。
library(car)
scatterplot.matrix(~x1+x10+x11+x2+x3+x4+x6+x7+x8+x9 | x5, reg.line=lm, smooth=TRUE, span=0.5, diagonal= 'histogram', by.groups=TRUE, data=region)
変数x5はx4がプラスなら+、マイナスならーと変換したものである。
エクセルのif関数を使用(よく使う)
G7:=IF(F7>0,"+",IF(F7=0,"0","-"))
最下行までコピーする。
このx4を目的変数にして、CART(決定木、回帰木)を行う
変数x5を除くこと。
ライブラリーの読み込み
library(rpart)
regt<-rpart(x4~x1+x2+x3+x6+x7+x8+x9+x10+x11,data=region)
regt
plot(regt,margin=0.1)
text(regt,use.n=T)
何かわかったことがあるだろうか?
ここまで例を参考に、新たな変数を追加したり削除したり、加工したりして各自で絵を描いてみてください。
数字を眺めているだけでは分からなかいことでも、多変量散布図やCARTを描くことで何か、面白い情報が発見できるかもしれません。
~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~
前回、描画できなかった人は、描画してupしといてください。
前回の作業のトレース ↓
タイタニック号データの描画例
titn<-read.table("clipboard",header=T)
names(titn)
summary(titn)
titnr<-rpart(survived~pclass+age+sex,data=titn)
plot(titnr,margin=0.1)
text(titnr,use.n=T)
結果を見やすいように改良する
変数”suvived”は0か1の2値データなので、
関数:factor()を使って、2値化する。
titnr<-rpart(factor(survived)~pclass+age+sex,data=titn)
plot(titnr,margin=0.1)
text(titnr,use.n=T)
titnr
Posted by ryu908 at
16:39
│Comments(18)
これまでの復習のような
基本的にただで無料のフリーな高機能統計ソフト「R」を中心につかってきました。
これは自宅で、職場でDLして使えます。
SASやTSPなどの市販ソフトと違うところであり、強力なグラフィックも魅力的です。
本演習の最初に"R on Web"を使用しましたが、これはDLしなくてもnetに接続していれば使えます。
さて、最初のほうでCARTというのを使ったのを覚えてますか。
これは別名ツリーモデルともいいます。ここでもう一度この手法を復讐します。
データマイニングのわかりやすい事例という位置づけです。
しかもRコマンダーではすぐには作れません。
このモデルは
目的変数←説明変数
という回帰モデルの一種で、データに潜在する構造を可視化するものです。
Rには
tree
party
mvpart
といったパッケージがある(これもRの開発と成長の証し)。
関数rpart()を使いました。
rpart(式、データ、推計方法)
このデータの樹形図(ツリーモデル)を描いてくだされ。
ただし
目的変数:class
説目変数:V1からV9
この例題は「RとRコマンダーではじめる多変量解析」p137~p141からとった。
琉大図書館のOPAC蔵書検索から、webcatに飛ばされたけど所蔵図書館一覧をみると県内では沖国にしかないようです。一読をお勧めします。



次のデータに対して同じことをしてみましょう的問題。

基本的にただで無料のフリーな高機能統計ソフト「R」を中心につかってきました。
これは自宅で、職場でDLして使えます。
SASやTSPなどの市販ソフトと違うところであり、強力なグラフィックも魅力的です。
本演習の最初に"R on Web"を使用しましたが、これはDLしなくてもnetに接続していれば使えます。
さて、最初のほうでCARTというのを使ったのを覚えてますか。
これは別名ツリーモデルともいいます。ここでもう一度この手法を復讐します。
データマイニングのわかりやすい事例という位置づけです。
しかもRコマンダーではすぐには作れません。
このモデルは
目的変数←説明変数
という回帰モデルの一種で、データに潜在する構造を可視化するものです。
Rには
tree
party
mvpart
といったパッケージがある(これもRの開発と成長の証し)。
関数rpart()を使いました。
rpart(式、データ、推計方法)
このデータの樹形図(ツリーモデル)を描いてくだされ。
ただし
目的変数:class
説目変数:V1からV9
この例題は「RとRコマンダーではじめる多変量解析」p137~p141からとった。
琉大図書館のOPAC蔵書検索から、webcatに飛ばされたけど所蔵図書館一覧をみると県内では沖国にしかないようです。一読をお勧めします。



次のデータに対して同じことをしてみましょう的問題。

Posted by ryu908 at
18:58
│Comments(19)
1.Rコマンダーを使ってみる。
ここをみる
2.統計データのサイト
沖縄県統計課
ここに他の都道府県や総務省、日本統計年鑑へのリンクがある。
新聞社の選挙関連記事
日銀那覇支店
日銀那覇支店にもいい情報があります。特に短観の沖縄版。
統計ソフトで処理するとき、日銀では利用しやすい形で、長期統計を整備
しています。探してみてください。
琉球銀行や沖縄銀行でも統計データ(月次ベース)を整備しています。
民間では東洋経済や日経新聞でもデータを公開している(はず)。
経済データ解析のための情報処理
① データ公開サイトの確認
どの機関がどのようなデータを収集し公開しているか。
② 興味ある分野の閲覧
対象サイトの公開情報から興味ある分野を調べる。
③ 経済データ情報の前処理
公開されている情報はそのままですぐに
使用できるのはまれで何らかの処理が必要。
行列を揃えたり、必要な部分を切りだしたり
加工して必要な情報処理を行う。
→ データはExcelで管理しread.table("clipboard")関数で渡す。
④ データを眺める
取り出して必要な情報処理を加えたデータを、
様々な方法で統計グラフに描画し、データの
傾向や特徴をおおまかに把握する。
⑤ 分析する(描画+記述する)
対象データに対して適切な統計処理を施す。
分類したり、要約したりして特徴を浮かび上がらせる。
あるいは予測を試みる。
⑥ 各自のサイトにUPする
結果は作業の流れが分かるように各自のブログに公開。
分析結果を出力するまでのプロセスを一連の記事として
公開する。
内容よりも作業のプロセスを評価する。
080806修復している?

ここをみる
2.統計データのサイト
沖縄県統計課
ここに他の都道府県や総務省、日本統計年鑑へのリンクがある。
新聞社の選挙関連記事
日銀那覇支店
日銀那覇支店にもいい情報があります。特に短観の沖縄版。
統計ソフトで処理するとき、日銀では利用しやすい形で、長期統計を整備
しています。探してみてください。
琉球銀行や沖縄銀行でも統計データ(月次ベース)を整備しています。
民間では東洋経済や日経新聞でもデータを公開している(はず)。
経済データ解析のための情報処理
① データ公開サイトの確認
どの機関がどのようなデータを収集し公開しているか。
② 興味ある分野の閲覧
対象サイトの公開情報から興味ある分野を調べる。
③ 経済データ情報の前処理
公開されている情報はそのままですぐに
使用できるのはまれで何らかの処理が必要。
行列を揃えたり、必要な部分を切りだしたり
加工して必要な情報処理を行う。
→ データはExcelで管理しread.table("clipboard")関数で渡す。
④ データを眺める
取り出して必要な情報処理を加えたデータを、
様々な方法で統計グラフに描画し、データの
傾向や特徴をおおまかに把握する。
⑤ 分析する(描画+記述する)
対象データに対して適切な統計処理を施す。
分類したり、要約したりして特徴を浮かび上がらせる。
あるいは予測を試みる。
⑥ 各自のサイトにUPする
結果は作業の流れが分かるように各自のブログに公開。
分析結果を出力するまでのプロセスを一連の記事として
公開する。
内容よりも作業のプロセスを評価する。
080806修復している?

Posted by ryu908 at
09:15
│Comments(18)
Rに関する情報はすべてここにあります。→RjpWiki
周期性を見る
時間領域:自己相関
acf(変数名,lag.max=遅れ次数)
周波数領域:スペクトル(ピリオドグラム)
spectrum(変数名)
ここでは簡単に
パワースペクトルの周波数は(1/周期)でみる。
なので0が無限大(上昇下降といったトレンド)
0.5が2期(最小のデータは2個なので)とみる。

練習データ
1.ExcelのデータをRに読み込む
変数名がある場合は header=T を指定する。
2.変数の分離
「データセット$変数名」で取り出すのは面倒なので
attachを使う
3.画面を分割し、描画する
(1)5つに分割して、全変数を同時にプロットしてみる
(2)3分割し
①プロット
②自己相関関数
③スペクトル(ピリオドグラム)
を1画面に描画する
data
sunspot dataのexcelからRへの読み込みと
tsオブジェクトへの変換(1749年~1983)
decompose(TCSI分離)の実行

Rによる統計入門より



周期性を見る
時間領域:自己相関
acf(変数名,lag.max=遅れ次数)
周波数領域:スペクトル(ピリオドグラム)
spectrum(変数名)
ここでは簡単に
パワースペクトルの周波数は(1/周期)でみる。
なので0が無限大(上昇下降といったトレンド)
0.5が2期(最小のデータは2個なので)とみる。

練習データ
1.ExcelのデータをRに読み込む
変数名がある場合は header=T を指定する。
2.変数の分離
「データセット$変数名」で取り出すのは面倒なので
attachを使う
3.画面を分割し、描画する
(1)5つに分割して、全変数を同時にプロットしてみる
(2)3分割し
①プロット
②自己相関関数
③スペクトル(ピリオドグラム)
を1画面に描画する
data
sunspot dataのexcelからRへの読み込みと
tsオブジェクトへの変換(1749年~1983)
decompose(TCSI分離)の実行

Rによる統計入門より



Posted by ryu908 at
11:16
│Comments(21)
週の続き
時系列分析の例
これは時系列分析の例ですが図及び各種計算はすべて
Rで実行しています。
皆さんが開設したブログにおいても
こんな感じで沖縄経済(日本や外国でも構わないが)の分析例を
投稿掲載してオリジナルのコンテンツとして公開します。
それをもって今学期の最終目標(及び評価)とさせていただきます。
使う手法はこれまでに紹介したデーラマイニング技法や
これから紹介する時系列分析法を使用します。
Rのコードは公開済みですのでデータを入れ替えて
実行してみるだけです。
また、サンプルコードや復讐のための各種情報は
Rjpwiki
に十分過ぎるほどのストックがあります。
というわけで
そのつもりで
ここからは頑張っていきましょう。
時系列分析の例
これは時系列分析の例ですが図及び各種計算はすべて
Rで実行しています。
皆さんが開設したブログにおいても
こんな感じで沖縄経済(日本や外国でも構わないが)の分析例を
投稿掲載してオリジナルのコンテンツとして公開します。
それをもって今学期の最終目標(及び評価)とさせていただきます。
使う手法はこれまでに紹介したデーラマイニング技法や
これから紹介する時系列分析法を使用します。
Rのコードは公開済みですのでデータを入れ替えて
実行してみるだけです。
また、サンプルコードや復讐のための各種情報は
Rjpwiki
に十分過ぎるほどのストックがあります。
というわけで
そのつもりで
ここからは頑張っていきましょう。
Posted by ryu908 at
13:55
│Comments(19)
登録サイトの確認
アカウントがない方は早めに連絡してください。
今回のテーマ
経済学で扱うデータは基本的に2つに分けられる。
①.時系列データ(Time series data)
②.横断面データ(Cross section data)
クロスセクションは国別のデータとか個人別データ、店舗別データなどの時間と関係のないものであったが、時系列データとは年度別、月別、曜日別といった特定の指標の時間推移を示すものである。
なお両方同時に扱うものとしてプーリングデータ(パネルとか最近は言う)がある。
時系列(Wikipedia)
1.データの読み込み
read.table関数によるファイルの読み込み
read.table("ファイル名")
read.table("ファイル名",header=T)
(データの1行目に変数名がある場合「header=T」をつける)
まずExcelを起動する。
このデータをクリックして起動
ExcelにデータがA1からB492まであります。
これを直接、Rに取り込む。
データ範囲を選択してコピーする。
①コピーは編集メニューから選択する方法と
②「Ctrl」+「C」キーのどちらの方法でもよい。
コピーするということは、Windowsのメモリーに一時的に記憶/記録されているということである。
記憶されている場所をWindowsでは「クリップボード」という。
次にRを起動し
x<-read.table("clipboard")
と入力し、xの中身を確認する。Excelのスプレッドシートがクリップボード経由でRに代入されていることが分かる。
2.時系列データの解析
分析ではなく解析としました。
余談:時系列解析を極めたい方は赤池弘次「ダイナミックシステムの統計的解析と制御」をお勧めする。この本のプログラムはfortranだが、実はRに移植されており、R版TIMSACというパッケージで提供されている。琉大図書館には72年版があります。
さて読み込んだデータをまずグラフにして、眺めます。
plot(x)
なんか変な感じです。理由はExcelから読み込むとき、列番号と変数名:V1が自動的に付けられているからです。そこで
plot(x$V1)
これはxデータセットから変数V1だけを取り出すという意味です。
Rでは「データフレーム名$変数名」と$で区切って変数を認識させます。
これでは面倒なので
x1<-x$V1
x2<-x$V2
として変換します。
これで
plot(x1)
plot(x2)
で描画できます。次は同時に表示します。グラフエリアを2つに分割します。
par(mfrow=c(1,2))
これはグラフ制御用の関数で行方向に1行2列に分けるという意味です。
par(mfrow=c(2,1))
とすれば2行1列になる。
ここから時系列分析用のパッケージ「tseries」を使う。
→パッケージ:tseriesを読み込んでください。
時系列データはデータに時間要素が付く、特殊なものであり、Rでは
tsオブジェクト
という形式にすることで便利な使い方ができる。
ここでは月別データとして2000年1月から始まるものと仮定した。
tsx1<-ts(x1,start=c(2000),frequency=12)
plot(x1)
plot(tsx1)
上と下の違いを確認してください。
同様に
tsx2<-ts(x2,start=c(2000),frequency=12)
plot(x2)
plot(tsx2)
標本自己相関を求める。
acf(tsx1)
acf(tsx2)
decompose(tsx1)
plot(decompose(tsx1))
基本用語解説
・自己相関
・移動平均
・季節調整
・TCSI成分とde trend
・定常時系列
・非定常時系列
dcp<-decompose(tsx1)
tsx1r<-dcp$random
plot(tsx1)
plot(tsx1r)
3.予測
季節調整によってトレンドを除去すると前後12個のデータが欠落する。
のでデータを新たに定義しなおす。
tsx1r<-ts(tsx1r[7:486],start=c(2000),frequency=12)
なお、センサス局法X11、及びX12という方法を使えば、欠損値を補間してくれる。
(1)ARモデル
自己回帰分析をし、その結果をx1arというデータセットに保管する。
x1ar<-ar(tsx1r,method="ols")
summary(x1ar)
予測はpredictコマンドを使う。
x1arp<-predict(x1ar,n.ahead=12)
plot(x1arp$pred,lty=c(1,2))
ts.plot(x1arp$pred,tsx1r[469:480],lty=c(1,2))
参考文献:The R Book




(2)ARIMAモデル
AR:自己回帰
I:和分(階差と同じ)
MA:移動平均
xarma<-arima(tsx1r,order=c(2,0,1))
summary(xarma)
plot(xarma$residuals)
xarnap<-predict(xarma,n.ahead=12)
plot(predict(xarma,n.ahead=12)$pred)
ts.plot(xarmap$pred,tsx1r[469:480],lty=c(1,2))
4.課題
次のデータを使ってAR分析し、
12か月先の予測をした図を各自のブログにUPLOADしなさい。
沖縄県観光入域客数
1972(昭和47)1月~2006(平成18)12月まで
data points:420(=12×35)
アカウントがない方は早めに連絡してください。
今回のテーマ
経済学で扱うデータは基本的に2つに分けられる。
①.時系列データ(Time series data)
②.横断面データ(Cross section data)
クロスセクションは国別のデータとか個人別データ、店舗別データなどの時間と関係のないものであったが、時系列データとは年度別、月別、曜日別といった特定の指標の時間推移を示すものである。
なお両方同時に扱うものとしてプーリングデータ(パネルとか最近は言う)がある。
時系列(Wikipedia)
1.データの読み込み
read.table関数によるファイルの読み込み
read.table("ファイル名")
read.table("ファイル名",header=T)
(データの1行目に変数名がある場合「header=T」をつける)
まずExcelを起動する。
このデータをクリックして起動
ExcelにデータがA1からB492まであります。
これを直接、Rに取り込む。
データ範囲を選択してコピーする。
①コピーは編集メニューから選択する方法と
②「Ctrl」+「C」キーのどちらの方法でもよい。
コピーするということは、Windowsのメモリーに一時的に記憶/記録されているということである。
記憶されている場所をWindowsでは「クリップボード」という。
次にRを起動し
x<-read.table("clipboard")
と入力し、xの中身を確認する。Excelのスプレッドシートがクリップボード経由でRに代入されていることが分かる。
2.時系列データの解析
分析ではなく解析としました。
余談:時系列解析を極めたい方は赤池弘次「ダイナミックシステムの統計的解析と制御」をお勧めする。この本のプログラムはfortranだが、実はRに移植されており、R版TIMSACというパッケージで提供されている。琉大図書館には72年版があります。
さて読み込んだデータをまずグラフにして、眺めます。
plot(x)
なんか変な感じです。理由はExcelから読み込むとき、列番号と変数名:V1が自動的に付けられているからです。そこで
plot(x$V1)
これはxデータセットから変数V1だけを取り出すという意味です。
Rでは「データフレーム名$変数名」と$で区切って変数を認識させます。
これでは面倒なので
x1<-x$V1
x2<-x$V2
として変換します。
これで
plot(x1)
plot(x2)
で描画できます。次は同時に表示します。グラフエリアを2つに分割します。
par(mfrow=c(1,2))
これはグラフ制御用の関数で行方向に1行2列に分けるという意味です。
par(mfrow=c(2,1))
とすれば2行1列になる。
ここから時系列分析用のパッケージ「tseries」を使う。
→パッケージ:tseriesを読み込んでください。
時系列データはデータに時間要素が付く、特殊なものであり、Rでは
tsオブジェクト
という形式にすることで便利な使い方ができる。
ここでは月別データとして2000年1月から始まるものと仮定した。
tsx1<-ts(x1,start=c(2000),frequency=12)
plot(x1)
plot(tsx1)
上と下の違いを確認してください。
同様に
tsx2<-ts(x2,start=c(2000),frequency=12)
plot(x2)
plot(tsx2)
標本自己相関を求める。
acf(tsx1)
acf(tsx2)
decompose(tsx1)
plot(decompose(tsx1))
基本用語解説
・自己相関
・移動平均
・季節調整
・TCSI成分とde trend
・定常時系列
・非定常時系列
dcp<-decompose(tsx1)
tsx1r<-dcp$random
plot(tsx1)
plot(tsx1r)
3.予測
季節調整によってトレンドを除去すると前後12個のデータが欠落する。
のでデータを新たに定義しなおす。
tsx1r<-ts(tsx1r[7:486],start=c(2000),frequency=12)
なお、センサス局法X11、及びX12という方法を使えば、欠損値を補間してくれる。
(1)ARモデル
自己回帰分析をし、その結果をx1arというデータセットに保管する。
x1ar<-ar(tsx1r,method="ols")
summary(x1ar)
予測はpredictコマンドを使う。
x1arp<-predict(x1ar,n.ahead=12)
plot(x1arp$pred,lty=c(1,2))
ts.plot(x1arp$pred,tsx1r[469:480],lty=c(1,2))
参考文献:The R Book




(2)ARIMAモデル
AR:自己回帰
I:和分(階差と同じ)
MA:移動平均
xarma<-arima(tsx1r,order=c(2,0,1))
summary(xarma)
plot(xarma$residuals)
xarnap<-predict(xarma,n.ahead=12)
plot(predict(xarma,n.ahead=12)$pred)
ts.plot(xarmap$pred,tsx1r[469:480],lty=c(1,2))
4.課題
次のデータを使ってAR分析し、
12か月先の予測をした図を各自のブログにUPLOADしなさい。
沖縄県観光入域客数
1972(昭和47)1月~2006(平成18)12月まで
data points:420(=12×35)
Posted by ryu908 at
11:29
│Comments(20)
data miningとは視覚化visualizationである
Rを使ってデータマイニングを行うメリットの一つにデータの視覚化があります。
Ⅰ 回帰木による判別と予測
通常の回帰分析は
y=a+b x+c z ・・・
という具合に、
目的変数(被説明変数、従属変数):y
と
説明変数(独立変数):x,z ・・・
の式で示される。
そこで発想を変えて、データをふるいにかけてみる。
例えば、いくつかの条件を設定して
①条件Aを満たすか否か
②条件Bを満たすか否か
③条件Cを満たすか否か
・・・・・
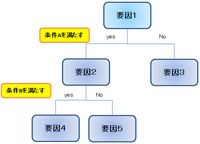
この例では、条件によってふるいにかけることで最終的に
3つのグループに分類される。
下の図は『Rで学ぶデータマイニング』p107
より、回帰木の例としてあげられているものです。

ようするにある条件(属性)に適合するか否かで。2つに分けていくやり方。最終的に残ったものが分類(予測)の結論的なものになる。
これは最初から自分でルールを定めるのでなく、機械的にふるいにかけて結論に至る方法ともいえ、データマイニングの特徴をよくあらわしている。
この手法の、重要な点は、「分ける」ということよりもむしろ
視覚化する
ということにある。
図からわかるように、木の根が伸びるような、枝が伸びるようなイメージであるため「回帰木」という。
英語でもCART(Classification And Regression Trees)というように木のイメージである。
因みに、こういう2分岐というのはアルゴリズム学習の基本中の基本にあるやつで、その分岐ルールに統計処理を行うのがCARTの魅力的なところ。実際は無意味なことであっても、なんとなく意味があるようにみせかけることができるので、悪用は厳禁だが...。
今回は、
① 前回同様irisデータを例題としてCARTを実行する。
② 外部からデータファイルを読み込む。
③ そのデータにCARTを適用する。
1.RでCARTするには「mvpart」、「rpart」の2つのパッケージを利用すればよい。書式は
>rpart(判別したい変数 ~ . , data=データフレーム名)
>rpart(判別したい変数 ~ 変数1 + 変数2 + ・・・. , data=データフレーム名)
詳細はHELPで確認しれ。
2.データファイルの読み込み方
方法はたくさんある。
データファイルの形式もASCII形式から、SASデータファーマット、Excelファイル、Accessファイルなどたくさんある。
とりあえずほとんどのOSに対応でき、特別なソフトも不要なASCII形式を取り上げる。
サンプルデータを各自の指定されたフォルダに保存する。
なお、ファイル/ディレクトリの作成/削除/移動
と
ファイルの保存場所の確認
はできるようにする。基本といってもバカにしない。WinXP以外のOSでもできますか?GUIでなければできない。
というのではあまりにもなさけない(と思う)。
せめて、かゆい所に手が届くようにしたいものです。
3.今回の課題
Rを使ってデータマイニングを行うメリットの一つにデータの視覚化があります。
Ⅰ 回帰木による判別と予測
通常の回帰分析は
y=a+b x+c z ・・・
という具合に、
目的変数(被説明変数、従属変数):y
と
説明変数(独立変数):x,z ・・・
の式で示される。

そこで発想を変えて、データをふるいにかけてみる。
例えば、いくつかの条件を設定して
①条件Aを満たすか否か
②条件Bを満たすか否か
③条件Cを満たすか否か
・・・・・

この例では、条件によってふるいにかけることで最終的に
3つのグループに分類される。
下の図は『Rで学ぶデータマイニング』p107
より、回帰木の例としてあげられているものです。

ようするにある条件(属性)に適合するか否かで。2つに分けていくやり方。最終的に残ったものが分類(予測)の結論的なものになる。
これは最初から自分でルールを定めるのでなく、機械的にふるいにかけて結論に至る方法ともいえ、データマイニングの特徴をよくあらわしている。
この手法の、重要な点は、「分ける」ということよりもむしろ
視覚化する
ということにある。
図からわかるように、木の根が伸びるような、枝が伸びるようなイメージであるため「回帰木」という。
英語でもCART(Classification And Regression Trees)というように木のイメージである。
因みに、こういう2分岐というのはアルゴリズム学習の基本中の基本にあるやつで、その分岐ルールに統計処理を行うのがCARTの魅力的なところ。実際は無意味なことであっても、なんとなく意味があるようにみせかけることができるので、悪用は厳禁だが...。
今回は、
① 前回同様irisデータを例題としてCARTを実行する。
② 外部からデータファイルを読み込む。
③ そのデータにCARTを適用する。
1.RでCARTするには「mvpart」、「rpart」の2つのパッケージを利用すればよい。書式は
>rpart(判別したい変数 ~ . , data=データフレーム名)
>rpart(判別したい変数 ~ 変数1 + 変数2 + ・・・. , data=データフレーム名)
詳細はHELPで確認しれ。
2.データファイルの読み込み方
方法はたくさんある。
データファイルの形式もASCII形式から、SASデータファーマット、Excelファイル、Accessファイルなどたくさんある。
とりあえずほとんどのOSに対応でき、特別なソフトも不要なASCII形式を取り上げる。
サンプルデータを各自の指定されたフォルダに保存する。
なお、ファイル/ディレクトリの作成/削除/移動
と
ファイルの保存場所の確認
はできるようにする。基本といってもバカにしない。WinXP以外のOSでもできますか?GUIでなければできない。
というのではあまりにもなさけない(と思う)。
せめて、かゆい所に手が届くようにしたいものです。
3.今回の課題
Posted by ryu908 at
17:26
│Comments(19)
ブログの登録が済んでいる方の一覧です。確認してください。
Web(Blog) site List
Rでデータマイニングを試みる。
参考文献:Rで学ぶデータマイニングⅠ
データマイニング(Data mining)とは?
最近、多変量解析という言葉を聞かないが、データマイニングというのはよく聞くし、書店や図書館でもよく見かける。
Rによるバイオインフォマティクスデータ解析という本には「データマイニング」の章があり、「データマイニングとは何か」という節があるが、いきなり
データマイニングの工程は,データの前処理、特徴抽出,教師なし学習,教師あり学習の四つの工程からなる。
という文章から始まる。ちなみに『Rで学ぶデータマイニングⅠ』では「データマイニングとは何か」という説明はなく、本全体から読み取るか、既に知っているというのが前提のようだ。
というわけで、データマイニングの概要を知る最良の書(と思う)は金鉱を掘り当てる統計学 だと思う。BLUE BACKSだが琉大図書館にありますので一読をお勧めします。この本はタイトルがデータマイニングを連想させないためか、知名度は低いようだ(BLUE BACKSで金鉱とくれば地学関連書と思う人が多かったのかもしれない)。
ここでは単純に、
ネット環境下で大量に集積するオンラインデータから、知識を発見する方法
とだけしておきます。
基本的にデータマイニングという手法があるわけでなく多変量解析やデータ解析の延長線上にあるものだろう。その昔、EDA(探索的データ解析)というのがでて流行らなかったが、Web時代のデータ解析という時代背景が異なるだけで考え方は同じじゃないかと思えて仕方がない。なお、『金鉱を掘り当てる統計学』では
・非線形性(non-linear)
・視覚化(data visualization)
・交差妥当化(cross validation)
・最適性、一意性のなさ
を、その特徴としてあげている。これは「データの前処理、特徴抽出,教師なし学習,教師あり学習の四つの工程」の異なる表現にすぎない。
そこで『Rによるバイオインフォマティクスデータ解析』からの引用を以下に列記します。
データの前処理
データの前処理は変量ごとに変動範囲を同等にすることで、特定の変量のみが多変量解析の結果に影響を及ぼすのを防ぐのが目的である。
特徴抽出
特徴抽出はデータ解析に必要のない変量の除去が目的で、欠損値の除去を行う。またt検定で外れ値を検出し処理する方法もあるが、個体差はけっして外れ値とは言えないので、不用意にデータを除去するべきではない。
教師なし学習
教師なし学習は多変量データの類似性に基いてデータを分類する手法である。主成分分析、階層クラスタリング、非階層クラスタリングなどが教師なし学習にあたる。このとき、類似性を判定させるために与えるデータ(変量)を説明変数という。
教師あり学習
教師あり学習とは、たとえば植物における花弁やがくの長さや幅といったさまざまな説明変数に対して、それぞれの品種といった目的変数が与えられた場合に、説明変数から目的変数を推定する関数を求める方法である。k-Nearest Neighbor(k-最近傍)法、SVM(Support Vector Machine)、 PLS (Partial Least Square)などがこれにあたる。なお、SOM(Self‐Organizing Map、自己組織化マップ)や、RandomForest法は両方の学習が可能である。
交差検証法
交差検証法(cross validation)は学習の精度を評価する手法である。与えられた元のデータセットをN等分し、そこから1組を抜き出してテストデータセットとし、残りのN-1組のデータセットを訓練用のデータセットとして学習を行い、1回目の学習精度を求め、これをN回繰り返した平均とする(豊田先生のは「交差妥当化」と訳しておられる)。
何のこっちゃ、と思うかもしれませんが、習うより慣れろ、です。頭で分かろうとするのではなく、実際に手を動かすことで、体感してみるのが手っ取り早い。
幸い、Rには標準的なテキストや古典的な論文のデータが用意されていますので、最初にそれを使います。
データ「iris」はFisherが1936年に発表したΓ判別分析」に関する論文で使われていたもので、「フイツシヤーのアヤメのデータ」という呼び名で有名なデータです、中身は3種類のアヤメの分類に関するデータで、
Sepal.Length がく片の長さ、数値型(単位はcm)
Sepal.Width がく片の幅、数値型(単位はcm)
Petal.Length 花びらの長さ、数値型(単位はcm)
Petal.Width 花びらの幅、数値型(単位はcm)
Species アヤメの種類(setosa,versicolor,virginicaの3種)、文字型
という5つの変数(各種50本ずつ、計150本分)が含まれています。
最初の4つは量的データ、最後の1つは名前なので質的データ(カテゴリー、因子)という
以下の3つの手順でデータを確認する。
1.x
2.edit(x)
3.library(relimp)
showData(x)
(パッケージのインストール方法)
Ⅰ データを要約する・層別するの手順
1.データをグラフにして眺める
2.要約統計量を算出して数値的なチェックを行う
3.興味のある部分(層)だけに絞りて.グラフの描写や統計量の算出を行う
具体的なWORK
①ヒストグラムを描く
②要約統計量の算出
③層別にヒストグラムを描く
④層別に要約統計量を算出する
⑤分割表の作成
Ⅱ 変数間の関連性をつかむ
4.データを2つのペアにする
5.2つのペアの散布図を描いて眺める
6.2つのペアの相関係数を算出する
7.興味のある部分(層)に絞って解析する
⑥散布図を描く
⑦相関係数を算出する
⑧3次元散布図の出力
本日の課題
3次元散布図を出力し、各自のブログにUPする。
Web(Blog) site List
Rでデータマイニングを試みる。
参考文献:Rで学ぶデータマイニングⅠ
データマイニング(Data mining)とは?
最近、多変量解析という言葉を聞かないが、データマイニングというのはよく聞くし、書店や図書館でもよく見かける。
Rによるバイオインフォマティクスデータ解析という本には「データマイニング」の章があり、「データマイニングとは何か」という節があるが、いきなり
データマイニングの工程は,データの前処理、特徴抽出,教師なし学習,教師あり学習の四つの工程からなる。
という文章から始まる。ちなみに『Rで学ぶデータマイニングⅠ』では「データマイニングとは何か」という説明はなく、本全体から読み取るか、既に知っているというのが前提のようだ。
というわけで、データマイニングの概要を知る最良の書(と思う)は金鉱を掘り当てる統計学 だと思う。BLUE BACKSだが琉大図書館にありますので一読をお勧めします。この本はタイトルがデータマイニングを連想させないためか、知名度は低いようだ(BLUE BACKSで金鉱とくれば地学関連書と思う人が多かったのかもしれない)。
ここでは単純に、
ネット環境下で大量に集積するオンラインデータから、知識を発見する方法
とだけしておきます。
基本的にデータマイニングという手法があるわけでなく多変量解析やデータ解析の延長線上にあるものだろう。その昔、EDA(探索的データ解析)というのがでて流行らなかったが、Web時代のデータ解析という時代背景が異なるだけで考え方は同じじゃないかと思えて仕方がない。なお、『金鉱を掘り当てる統計学』では
・非線形性(non-linear)
・視覚化(data visualization)
・交差妥当化(cross validation)
・最適性、一意性のなさ
を、その特徴としてあげている。これは「データの前処理、特徴抽出,教師なし学習,教師あり学習の四つの工程」の異なる表現にすぎない。
そこで『Rによるバイオインフォマティクスデータ解析』からの引用を以下に列記します。
データの前処理
データの前処理は変量ごとに変動範囲を同等にすることで、特定の変量のみが多変量解析の結果に影響を及ぼすのを防ぐのが目的である。
特徴抽出
特徴抽出はデータ解析に必要のない変量の除去が目的で、欠損値の除去を行う。またt検定で外れ値を検出し処理する方法もあるが、個体差はけっして外れ値とは言えないので、不用意にデータを除去するべきではない。
教師なし学習
教師なし学習は多変量データの類似性に基いてデータを分類する手法である。主成分分析、階層クラスタリング、非階層クラスタリングなどが教師なし学習にあたる。このとき、類似性を判定させるために与えるデータ(変量)を説明変数という。
教師あり学習
教師あり学習とは、たとえば植物における花弁やがくの長さや幅といったさまざまな説明変数に対して、それぞれの品種といった目的変数が与えられた場合に、説明変数から目的変数を推定する関数を求める方法である。k-Nearest Neighbor(k-最近傍)法、SVM(Support Vector Machine)、 PLS (Partial Least Square)などがこれにあたる。なお、SOM(Self‐Organizing Map、自己組織化マップ)や、RandomForest法は両方の学習が可能である。
交差検証法
交差検証法(cross validation)は学習の精度を評価する手法である。与えられた元のデータセットをN等分し、そこから1組を抜き出してテストデータセットとし、残りのN-1組のデータセットを訓練用のデータセットとして学習を行い、1回目の学習精度を求め、これをN回繰り返した平均とする(豊田先生のは「交差妥当化」と訳しておられる)。
何のこっちゃ、と思うかもしれませんが、習うより慣れろ、です。頭で分かろうとするのではなく、実際に手を動かすことで、体感してみるのが手っ取り早い。
幸い、Rには標準的なテキストや古典的な論文のデータが用意されていますので、最初にそれを使います。
データ「iris」はFisherが1936年に発表したΓ判別分析」に関する論文で使われていたもので、「フイツシヤーのアヤメのデータ」という呼び名で有名なデータです、中身は3種類のアヤメの分類に関するデータで、
Sepal.Length がく片の長さ、数値型(単位はcm)
Sepal.Width がく片の幅、数値型(単位はcm)
Petal.Length 花びらの長さ、数値型(単位はcm)
Petal.Width 花びらの幅、数値型(単位はcm)
Species アヤメの種類(setosa,versicolor,virginicaの3種)、文字型
という5つの変数(各種50本ずつ、計150本分)が含まれています。
最初の4つは量的データ、最後の1つは名前なので質的データ(カテゴリー、因子)という
以下の3つの手順でデータを確認する。
1.x
2.edit(x)
3.library(relimp)
showData(x)
(パッケージのインストール方法)
Ⅰ データを要約する・層別するの手順
1.データをグラフにして眺める
2.要約統計量を算出して数値的なチェックを行う
3.興味のある部分(層)だけに絞りて.グラフの描写や統計量の算出を行う
具体的なWORK
①ヒストグラムを描く
②要約統計量の算出
③層別にヒストグラムを描く
④層別に要約統計量を算出する
⑤分割表の作成
Ⅱ 変数間の関連性をつかむ
4.データを2つのペアにする
5.2つのペアの散布図を描いて眺める
6.2つのペアの相関係数を算出する
7.興味のある部分(層)に絞って解析する
⑥散布図を描く
⑦相関係数を算出する
⑧3次元散布図の出力
本日の課題
3次元散布図を出力し、各自のブログにUPする。
Posted by ryu908 at
12:18
│Comments(19)
blog開設した方は、前回の記事を参照してください。
学籍番号とリンク先が対応しているか確認してください。間違っていたら申し出てくさい。修正します。
~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~
Rを使ってみよう。
RWiki
・RWikiはRubyで開発されたWikiで、Rの日本語に関する情報のほとんどが網羅されている。
・Rの日本語文献は最近数多く出版されているが、
The R Book(WebCatPlus)
がおすすめ。琉大図書館にはないが、沖国、沖大、沖縄高専にはあるようだ。不思議。
他の参考文献に関してはRWikiを参考にしてください。
ところでSASにしろSPSSにしろ、Sも目の前のマシンにインストールしなければならない。Rもしかり。とことろがRには"R on Web"というサイトがあり、ある程度のことは体験することができる。
"R on Web"なら、ブラウザさえあれば、どこででもRを実行できる。
R on Web
上記リンクを開いてください。こんなかんじになっていると思います。

この部分をマウスで範囲選択してコピーします。

今度はコードを記述するボックス部分に貼り付けて、ボックス下の「Submit」ボタンを押してください。

しばらくすると計算結果が出力されます。
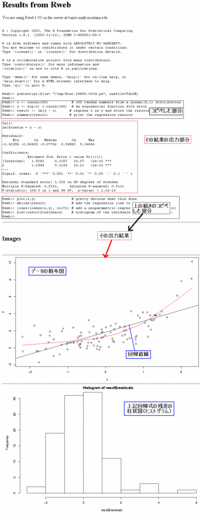
コードの説明
x <- rnorm(100)
・rnormは正規乱数を発生させる関数で、ここでは100個の正規乱数を発生させ、xという変数に代入しています。
・代入は「=」ではなく「<-」で記述します。
y <- exp(x) + rnorm(100)
・xを指数変換し、それに100個の正規乱数を加える。こうしてできた系列をyという変数に代入。
result <- lm(y ~ x)
・lmは線形回帰の関数で「y=a+b・x」という式を当てはめ、aとbを推計する。推計結果をresultという変数の代入。
・このように推計式の場合、Rは「=」でなく「~」とイコールでなく、チルダを用いる。
summary(result)
・summaryはその名の通り、結果を要約して出力する。回帰結果が保持されているresultの内容を表示する。
plot(x,y)
・xとyをプロット(散布図)する。
abline(result)
・resultの中にある回帰係数aとbを使った回帰線を描き、プロットグラフに追加する。
lines(lowess(x,y), col=2)
・Rには多くの平滑化関数があるが、その中の一つで、colは色を指定し、結果をlineで描画している。
hist(result$residuals)
・histはその名の通りヒストグラムを描画する関数で、回帰計算の結果が保持されているresultから残差系列を抜き出して、描画している。
・residualsはlm関数の結果として出力される数値系列で、その名の通り残差系列である。
Rの書式では、ある処理を施したあと、その結果として出力される数値等に対して、「キャラクターダラー$その変数名:ここではresult$residuals」というように指定することで結果の一部を取り出す。
今回の課題
・1番目にやること
R on Webで実行したことを、クライアントマシンにインストールされているRで実行してください。
・2番目にやること
まず、xとyを出力してみる。
今度は各々の系列に1を加え、
xを対数変換して、
回帰分析してみる。
その上で上と同じ、回帰直線のあてはめと、図の出力を実行する。
summary(result)
で出力された結果と
2つの図(回帰直線+散布図とヒストグラム)
を各自のblogに投稿(upload)してください。
:hint
{
x <- 1+rnorm(100)
y <- exp(x) + 1 + rnorm(100)
result <- lm(log(y) ~ log(x))
}
以上の課題ができたら、ここのコメント欄に
① 学籍番号
② URL
③ 「課題終了」
と書き込んでください。
学籍番号とリンク先が対応しているか確認してください。間違っていたら申し出てくさい。修正します。
~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~
Rを使ってみよう。
RWiki
・RWikiはRubyで開発されたWikiで、Rの日本語に関する情報のほとんどが網羅されている。
・Rの日本語文献は最近数多く出版されているが、
The R Book(WebCatPlus)
がおすすめ。琉大図書館にはないが、沖国、沖大、沖縄高専にはあるようだ。不思議。
他の参考文献に関してはRWikiを参考にしてください。
ところでSASにしろSPSSにしろ、Sも目の前のマシンにインストールしなければならない。Rもしかり。とことろがRには"R on Web"というサイトがあり、ある程度のことは体験することができる。
"R on Web"なら、ブラウザさえあれば、どこででもRを実行できる。
R on Web
上記リンクを開いてください。こんなかんじになっていると思います。

この部分をマウスで範囲選択してコピーします。

今度はコードを記述するボックス部分に貼り付けて、ボックス下の「Submit」ボタンを押してください。

しばらくすると計算結果が出力されます。

コードの説明
x <- rnorm(100)
・rnormは正規乱数を発生させる関数で、ここでは100個の正規乱数を発生させ、xという変数に代入しています。
・代入は「=」ではなく「<-」で記述します。
y <- exp(x) + rnorm(100)
・xを指数変換し、それに100個の正規乱数を加える。こうしてできた系列をyという変数に代入。
result <- lm(y ~ x)
・lmは線形回帰の関数で「y=a+b・x」という式を当てはめ、aとbを推計する。推計結果をresultという変数の代入。
・このように推計式の場合、Rは「=」でなく「~」とイコールでなく、チルダを用いる。
summary(result)
・summaryはその名の通り、結果を要約して出力する。回帰結果が保持されているresultの内容を表示する。
plot(x,y)
・xとyをプロット(散布図)する。
abline(result)
・resultの中にある回帰係数aとbを使った回帰線を描き、プロットグラフに追加する。
lines(lowess(x,y), col=2)
・Rには多くの平滑化関数があるが、その中の一つで、colは色を指定し、結果をlineで描画している。
hist(result$residuals)
・histはその名の通りヒストグラムを描画する関数で、回帰計算の結果が保持されているresultから残差系列を抜き出して、描画している。
・residualsはlm関数の結果として出力される数値系列で、その名の通り残差系列である。
Rの書式では、ある処理を施したあと、その結果として出力される数値等に対して、「キャラクターダラー$その変数名:ここではresult$residuals」というように指定することで結果の一部を取り出す。
今回の課題
・1番目にやること
R on Webで実行したことを、クライアントマシンにインストールされているRで実行してください。
・2番目にやること
まず、xとyを出力してみる。
今度は各々の系列に1を加え、
xを対数変換して、
回帰分析してみる。
その上で上と同じ、回帰直線のあてはめと、図の出力を実行する。
summary(result)
で出力された結果と
2つの図(回帰直線+散布図とヒストグラム)
を各自のblogに投稿(upload)してください。
:hint
{
x <- 1+rnorm(100)
y <- exp(x) + 1 + rnorm(100)
result <- lm(log(y) ~ log(x))
}
以上の課題ができたら、ここのコメント欄に
① 学籍番号
② URL
③ 「課題終了」
と書き込んでください。
Posted by ryu908 at
19:49
│Comments(22)
| S | M | T | W | T | F | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
お気に入り
最新記事







カテゴリー